library(lavaan)This is lavaan 0.6-19
lavaan is FREE software! Please report any bugs.lst <- '
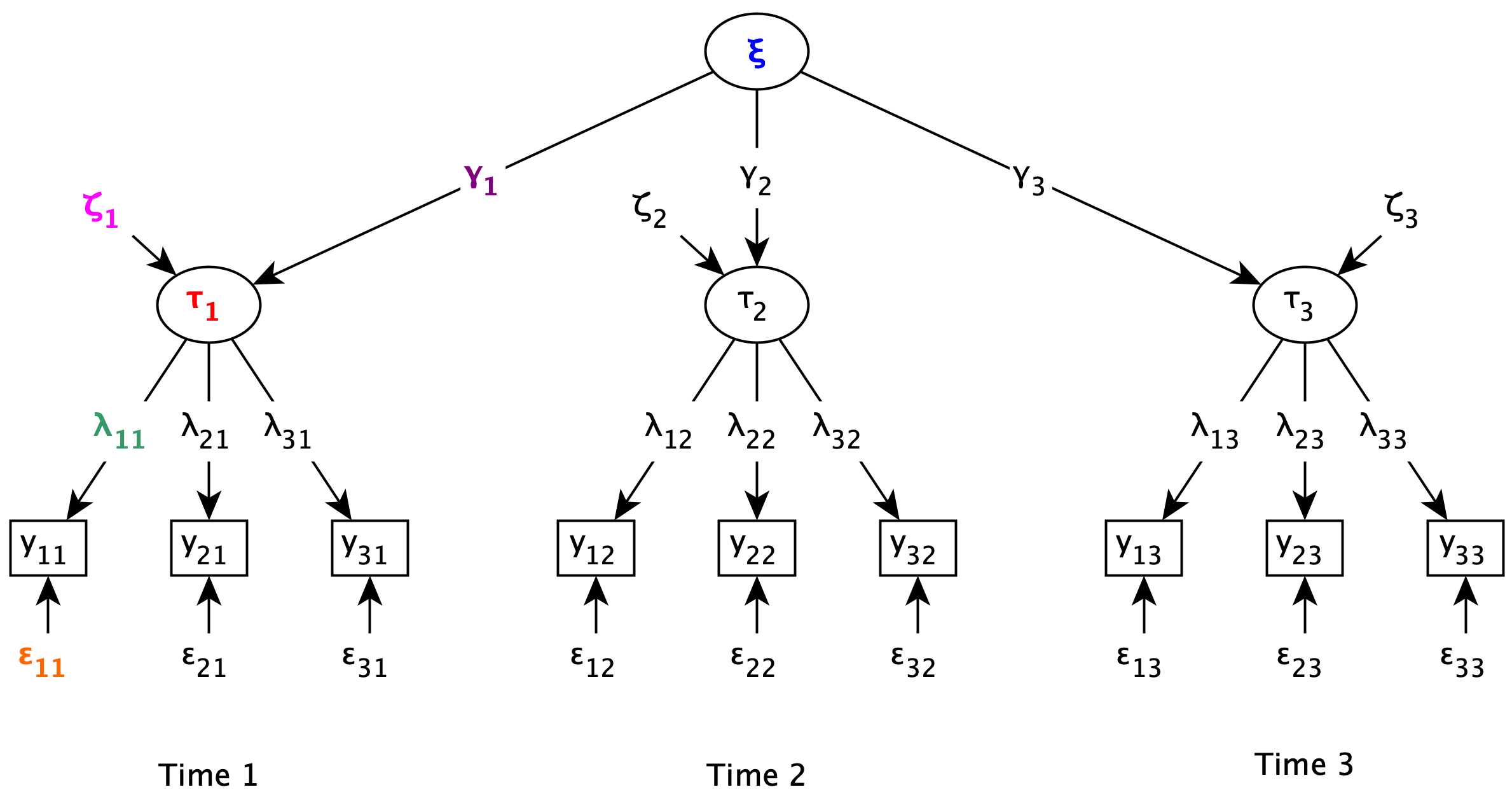
state1 =~ y_11 + y_21 + y_31 + y_41 + y_51
state2 =~ y_12 + y_22 + y_32 + y_42 + y_52
state3 =~ y_13 + y_23 + y_33 + y_43 + y_53
state4 =~ y_14 + y_24 + y_34 + y_44 + y_54
trait =~ state1 + state2 + state3 + state4
'
lst_fit <- cfa(lst, data = dat, estimator = "MLR")
summary(lst_fit, standardize = TRUE, rsquare = TRUE, fit.measures = TRUE)lavaan 0.6-19 ended normally after 156 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 44
Number of observations 784
Model Test User Model:
Standard Scaled
Test Statistic 177.185 176.092
Degrees of freedom 166 166
P-value (Chi-square) 0.262 0.281
Scaling correction factor 1.006
Yuan-Bentler correction (Mplus variant)
Model Test Baseline Model:
Test statistic 8716.493 8673.003
Degrees of freedom 190 190
P-value 0.000 0.000
Scaling correction factor 1.005
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.999 0.999
Tucker-Lewis Index (TLI) 0.998 0.999
Robust Comparative Fit Index (CFI) 0.999
Robust Tucker-Lewis Index (TLI) 0.999
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) 710.621 710.621
Scaling correction factor 1.022
for the MLR correction
Loglikelihood unrestricted model (H1) 799.214 799.214
Scaling correction factor 1.009
for the MLR correction
Akaike (AIC) -1333.243 -1333.243
Bayesian (BIC) -1128.009 -1128.009
Sample-size adjusted Bayesian (SABIC) -1267.731 -1267.731
Root Mean Square Error of Approximation:
RMSEA 0.009 0.009
90 Percent confidence interval - lower 0.000 0.000
90 Percent confidence interval - upper 0.019 0.019
P-value H_0: RMSEA <= 0.050 1.000 1.000
P-value H_0: RMSEA >= 0.080 0.000 0.000
Robust RMSEA 0.009
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.019
P-value H_0: Robust RMSEA <= 0.050 1.000
P-value H_0: Robust RMSEA >= 0.080 0.000
Standardized Root Mean Square Residual:
SRMR 0.023 0.023
Parameter Estimates:
Standard errors Sandwich
Information bread Observed
Observed information based on Hessian
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
state1 =~
y_11 1.000 0.181 0.653
y_21 0.914 0.060 15.190 0.000 0.166 0.642
y_31 0.891 0.063 14.213 0.000 0.162 0.622
y_41 0.702 0.056 12.588 0.000 0.127 0.524
y_51 1.138 0.076 15.013 0.000 0.206 0.719
state2 =~
y_12 1.000 0.366 0.886
y_22 1.160 0.034 34.148 0.000 0.424 0.904
y_32 1.121 0.033 34.003 0.000 0.410 0.905
y_42 1.303 0.034 37.951 0.000 0.477 0.920
y_52 1.250 0.036 34.968 0.000 0.457 0.916
state3 =~
y_13 1.000 0.277 0.813
y_23 0.728 0.034 21.145 0.000 0.201 0.719
y_33 0.797 0.034 23.541 0.000 0.220 0.744
y_43 0.706 0.035 20.127 0.000 0.195 0.700
y_53 0.524 0.031 17.172 0.000 0.145 0.609
state4 =~
y_14 1.000 0.116 0.503
y_24 1.469 0.134 10.972 0.000 0.171 0.660
y_34 1.200 0.121 9.949 0.000 0.140 0.577
y_44 1.184 0.123 9.656 0.000 0.138 0.567
y_54 1.010 0.106 9.554 0.000 0.117 0.514
trait =~
state1 1.000 0.742 0.742
state2 2.627 0.175 14.998 0.000 0.966 0.966
state3 1.816 0.135 13.453 0.000 0.883 0.883
state4 0.594 0.065 9.175 0.000 0.687 0.687
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.y_11 0.044 0.003 16.239 0.000 0.044 0.573
.y_21 0.039 0.002 16.727 0.000 0.039 0.588
.y_31 0.041 0.003 16.229 0.000 0.041 0.614
.y_41 0.043 0.002 18.435 0.000 0.043 0.725
.y_51 0.040 0.002 15.944 0.000 0.040 0.483
.y_12 0.037 0.002 16.451 0.000 0.037 0.215
.y_22 0.040 0.003 15.194 0.000 0.040 0.183
.y_32 0.037 0.002 16.767 0.000 0.037 0.180
.y_42 0.042 0.003 15.867 0.000 0.042 0.154
.y_52 0.040 0.002 16.365 0.000 0.040 0.162
.y_13 0.039 0.003 15.573 0.000 0.039 0.339
.y_23 0.038 0.002 18.156 0.000 0.038 0.483
.y_33 0.039 0.002 16.543 0.000 0.039 0.446
.y_43 0.040 0.002 17.951 0.000 0.040 0.510
.y_53 0.036 0.002 17.327 0.000 0.036 0.629
.y_14 0.040 0.002 16.607 0.000 0.040 0.747
.y_24 0.038 0.003 14.319 0.000 0.038 0.565
.y_34 0.039 0.002 16.415 0.000 0.039 0.667
.y_44 0.040 0.002 17.513 0.000 0.040 0.679
.y_54 0.038 0.002 17.359 0.000 0.038 0.736
.state1 0.015 0.002 7.767 0.000 0.449 0.449
.state2 0.009 0.004 2.547 0.011 0.067 0.067
.state3 0.017 0.002 7.041 0.000 0.219 0.219
.state4 0.007 0.001 6.113 0.000 0.528 0.528
trait 0.018 0.002 7.442 0.000 1.000 1.000
R-Square:
Estimate
y_11 0.427
y_21 0.412
y_31 0.386
y_41 0.275
y_51 0.517
y_12 0.785
y_22 0.817
y_32 0.820
y_42 0.846
y_52 0.838
y_13 0.661
y_23 0.517
y_33 0.554
y_43 0.490
y_53 0.371
y_14 0.253
y_24 0.435
y_34 0.333
y_44 0.321
y_54 0.264
state1 0.551
state2 0.933
state3 0.781
state4 0.472# Modellimplizierte Varianz-Kovarianz-Matrix
fitted(lst_fit)$cov
y_11 y_21 y_31 y_41 y_51 y_12 y_22 y_32 y_42 y_52 y_13 y_23
y_11 0.077
y_21 0.030 0.067
y_31 0.029 0.027 0.068
y_41 0.023 0.021 0.021 0.059
y_51 0.037 0.034 0.033 0.026 0.082
y_12 0.048 0.043 0.042 0.033 0.054 0.171
y_22 0.055 0.050 0.049 0.039 0.063 0.155 0.220
y_32 0.053 0.049 0.048 0.037 0.061 0.150 0.174 0.205
y_42 0.062 0.057 0.055 0.043 0.071 0.175 0.202 0.196 0.269
y_52 0.059 0.054 0.053 0.042 0.068 0.167 0.194 0.188 0.218 0.250
y_13 0.033 0.030 0.029 0.023 0.037 0.086 0.100 0.097 0.113 0.108 0.116
y_23 0.024 0.022 0.021 0.017 0.027 0.063 0.073 0.070 0.082 0.079 0.056 0.078
y_33 0.026 0.024 0.023 0.018 0.030 0.069 0.080 0.077 0.090 0.086 0.061 0.044
y_43 0.023 0.021 0.021 0.016 0.026 0.061 0.071 0.068 0.079 0.076 0.054 0.039
y_53 0.017 0.016 0.015 0.012 0.020 0.045 0.052 0.051 0.059 0.057 0.040 0.029
y_14 0.011 0.010 0.010 0.008 0.012 0.028 0.033 0.032 0.037 0.035 0.020 0.014
y_24 0.016 0.014 0.014 0.011 0.018 0.041 0.048 0.046 0.054 0.052 0.029 0.021
y_34 0.013 0.012 0.011 0.009 0.015 0.034 0.039 0.038 0.044 0.042 0.023 0.017
y_44 0.013 0.012 0.011 0.009 0.014 0.033 0.039 0.037 0.044 0.042 0.023 0.017
y_54 0.011 0.010 0.010 0.008 0.012 0.029 0.033 0.032 0.037 0.036 0.020 0.014
y_33 y_43 y_53 y_14 y_24 y_34 y_44 y_54
y_11
y_21
y_31
y_41
y_51
y_12
y_22
y_32
y_42
y_52
y_13
y_23
y_33 0.088
y_43 0.043 0.078
y_53 0.032 0.028 0.057
y_14 0.016 0.014 0.010 0.054
y_24 0.023 0.020 0.015 0.020 0.067
y_34 0.019 0.017 0.012 0.016 0.024 0.059
y_44 0.018 0.016 0.012 0.016 0.023 0.019 0.059
y_54 0.016 0.014 0.010 0.014 0.020 0.016 0.016 0.052